在数据科学和机器学习的领域中,Bias(偏差)是一个至关重要的概念,它不仅影响着模型的性能,还直接关系到模型在实际应用中的可靠性和公平性,本文将深入探讨Bias指标的内涵、类型、评估方法以及如何有效应对Bias,以促进更加公正和准确的数据分析。
Bias的定义与重要性
Bias指的是在数据收集、预处理、模型训练或评估过程中,由于人为因素或系统性的错误而导致的预测或决策的倾向性偏差,这种偏差可能源于多种因素,如性别、种族、地域等社会因素,也可能源于算法设计或数据处理过程中的不当操作,在数据科学中,识别和减少Bias是确保模型公平性和可靠性的关键步骤。
Bias的类型
-
选择偏差(Selection Bias):指在数据收集阶段,由于样本选择不当而导致的偏差,只从某个特定地区或特定群体中收集数据,导致样本不具代表性。
-
处理偏差(Processing Bias):在数据预处理或特征工程阶段引入的偏差,对某些特征进行不恰当的标准化或归一化处理,导致某些群体被不公平地对待。
-
模型偏差(Model Bias):由于模型设计或训练过程中的不当操作导致的偏差,使用不均衡的数据集训练分类器,可能导致对少数群体的预测性能下降。
-
预测偏差(Prediction Bias):模型预测结果与实际值之间的偏差,这可能由模型本身的局限性或输入数据的偏差引起。

Bias的评估方法
-
统计检验法:通过统计方法如t检验、卡方检验等,比较不同群体在模型预测结果上的差异,以评估Bias的存在与否。
-
混淆矩阵分析:在分类问题中,通过计算不同类别的真正例(TP)、假正例(FP)、真反例(TN)和假反例(FN)的数目,并计算精确度、召回率等指标,来评估模型对不同群体的预测性能。
-
公平性指标:如计算不同性别、种族等群体的预测结果的差异(如差异率、差异比),以量化Bias的程度,常用的指标包括平均绝对偏差(MAE)、均方误差(MSE)以及更高级的公平性指标如Equal Opportunity、Demographic Parity等。
-
SHAP值分析:SHAP(SHapley Additive exPlanations)是一种解释机器学习模型输出的方法,通过计算每个特征对预测结果的影响程度,来识别哪些特征可能引入了Bias。
应对Bias的策略
-
数据集的多样性与代表性:确保数据集在性别、种族、地域等方面具有足够的多样性和代表性,以减少选择偏差,可以通过数据增强、重采样等技术来增加数据的多样性。

-
公平性约束的优化算法:在模型训练过程中加入公平性约束,如使用Fairness-Aware Machine Learning算法,使模型在优化性能的同时考虑不同群体的公平性。
-
特征选择与预处理:在特征选择和预处理阶段,应避免对某些群体进行不公平的对待,使用无偏的标准化方法(如Z-score标准化)代替基于均值和标准差的归一化方法。
-
模型解释与调试:利用SHAP值等工具对模型进行解释和调试,识别并减少引入Bias的特征和操作,对于发现的问题进行迭代优化,直至达到满意的公平性水平。
-
持续监控与评估:建立持续的监控机制,定期对模型的预测结果进行公平性评估和调整,这包括对不同群体在不同时间点的预测结果进行跟踪和分析,及时发现并解决新的Bias问题。
案例分析:贷款审批中的Bias问题
在贷款审批的场景中,如果模型仅基于申请人的信用评分和收入水平进行决策,可能会因性别、种族等因素而引入Bias,一项研究表明,在传统的信用评分模型中,女性申请人的贷款被拒绝率往往高于男性,即使她们的信用评分和收入水平相同,这显然是一个典型的模型Bias问题。

为了解决这一问题,可以采取以下策略:通过收集更全面的数据(如教育背景、职业信息等),增加数据的多样性和代表性;采用Fairness-Aware Machine Learning算法对模型进行训练,确保不同性别和种族的申请人在贷款审批中的公平性;利用SHAP值分析识别并去除引入Bias的特征和操作,通过这些措施,可以显著提高贷款审批模型的公平性和可靠性。
结论与展望
在数据科学和机器学习的实践中,Bias是一个不容忽视的问题,它不仅影响模型的性能和可靠性,还可能引发社会不公和信任危机,我们必须高度重视Bias的识别和应对工作,通过采用多样化的数据集、公平性约束的优化算法、特征选择与预处理等策略以及持续的监控与评估机制,我们可以有效减少Bias的影响,提高模型的公平性和可靠性,随着技术的不断进步和算法的不断优化,我们有理由相信能够构建出更加公正、准确和可靠的机器学习模型,为社会发展贡献更大的力量。
转载请注明出处: 光城-个人学习记录
本文的链接地址: http://hangzhou.lightown.cn/post-916.html
本文最后发布于2025年04月10日22:22,已经过了25天没有更新,若内容或图片失效,请留言反馈
-

探索双成药业股票,潜力与挑战并存的医药蓝海
在当今全球医药行业快速发展的背景下,作为一家专注于生物制药和化学药品研发、生产和销售的企业——双成药业(股票代码:XXX),正以其独特的创新能力和市场布局,在激烈的市场竞争中崭露头角,本文将深入剖析双成药业股票的当前状况、市场前景、以及面临的挑战与机遇,旨在为投资者提供一份全面而深入的参考,双成药业概况及业务布……
2025/04/10
-
民生银行高管,引领金融创新,守护民生福祉的领航者
在当今复杂多变的全球经济环境中,中国银行业作为国家经济体系的重要支柱,其健康发展直接关系到国家金融安全与民生福祉,中国民生银行,作为一家以服务大众为己任、致力于小微企业金融服务的全国性股份制商业银行,其高管的决策与行动不仅关乎银行自身的战略方向,更对促进社会经济发展、提升民众生活质量具有深远影响,本文将深入探讨……
2025/04/11
-
002236股票行情深度剖析,市场动态、技术分析与投资策略
在A股市场中,002236作为一只备受关注的股票,其行情走势不仅牵动着众多投资者的心弦,也成为了市场分析的重要对象,本文将通过市场动态、技术分析以及投资策略三个维度,对002236股票的近期表现进行深入剖析,旨在为投资者提供有价值的参考和洞见,市场动态:行业背景与政策影响002236所属的XX行业,近年来在政策……
2025/04/11
-
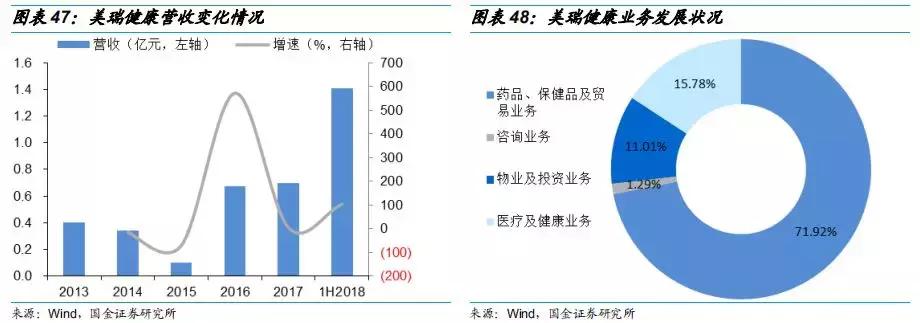
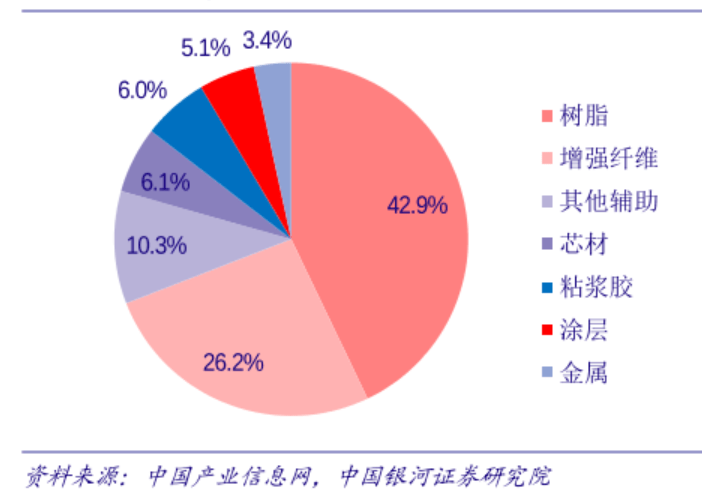
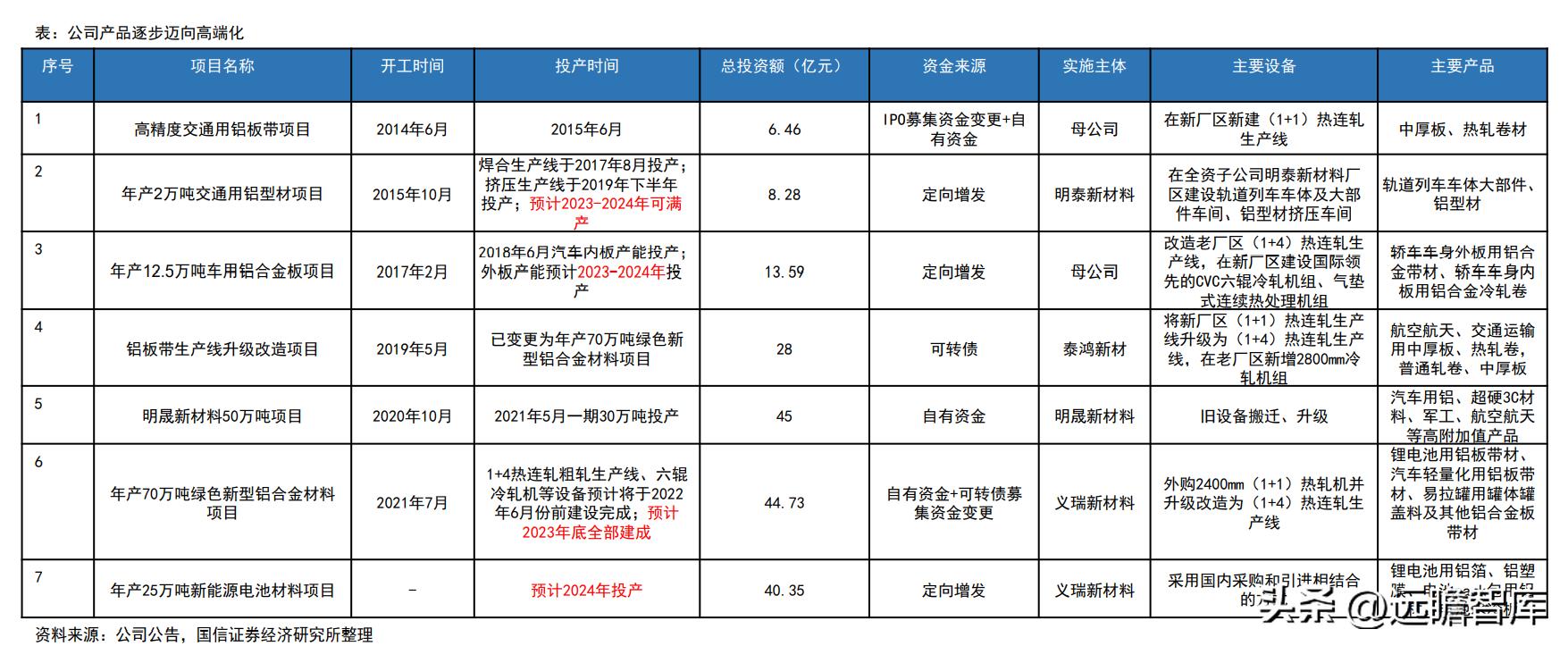
明泰铝业,铝行业的璀璨明珠与未来展望
在当今全球化的经济浪潮中,铝业作为重要的基础工业之一,不仅在传统建筑、交通领域发挥着不可替代的作用,更是在新能源、航空航天等高科技领域展现出广阔的应用前景,而在这片蓝海中,明泰铝业以其独特的竞争优势、创新的技术实力以及稳健的运营策略,成为了行业内的佼佼者,其股票表现也备受投资者关注,本文将深入剖析明泰铝业的现状……
2025/04/11
-
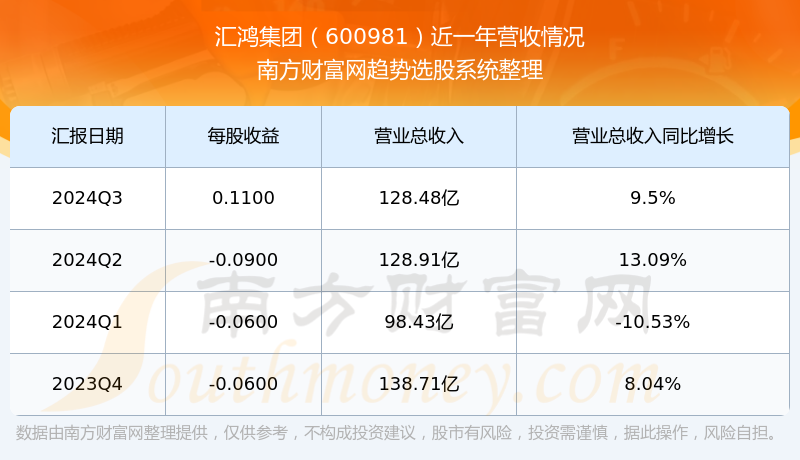
汇鸿股票,市场风云中的投资机遇与挑战
在瞬息万变的资本市场中,汇鸿股票作为一家在多个领域内拥有广泛业务布局的上市公司,始终是投资者关注的焦点,其股价的波动不仅反映了市场情绪的起伏,也映射出公司经营策略、行业趋势以及宏观经济环境等多重因素的影响,本文将深入探讨汇鸿股票的近期表现、背后的投资逻辑、面临的挑战以及未来的投资机遇,为投资者提供一份全面的参考……
2025/04/11
-
中铝国际股票,全球矿业巨头背后的投资机遇与风险考量
在全球经济一体化和资源需求日益增长的背景下,中铝国际(Chinalco International Corporation)作为中国铝业集团(Chinalco)的海外业务平台,不仅是中国乃至全球矿业领域的重要一员,其股票表现也成为了众多投资者关注的焦点,中铝国际不仅在铝土矿、氧化铝、原铝等产业链上拥有强大的资源……
2025/04/12
-
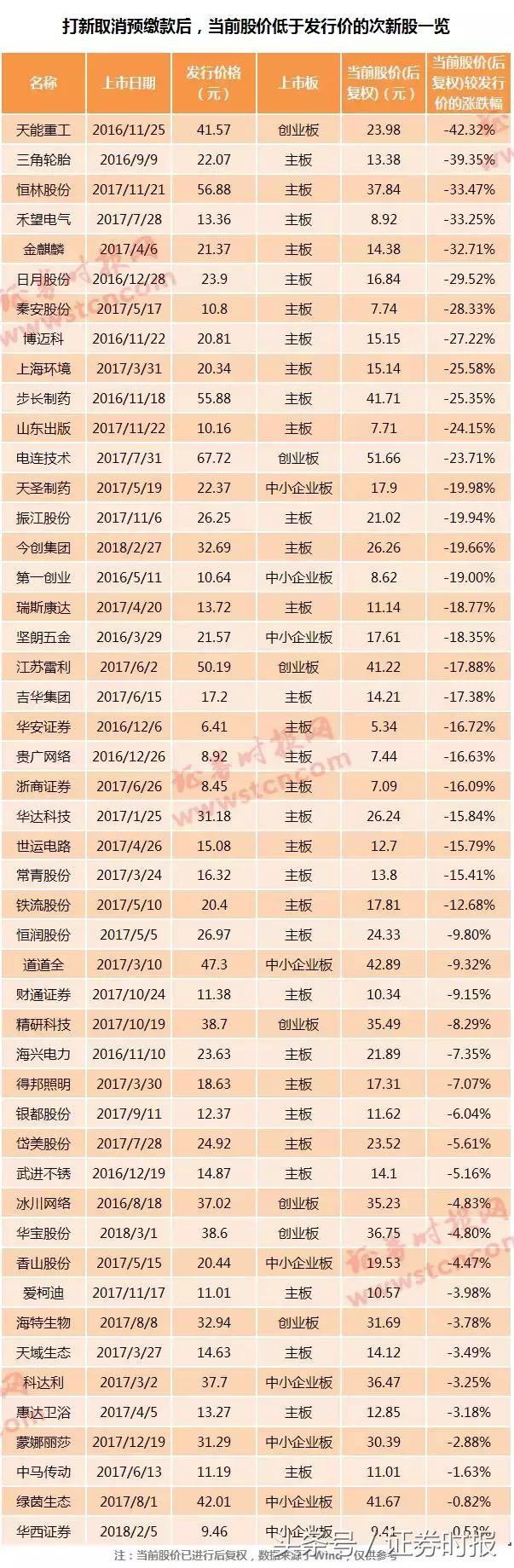
恒林股份股票行情,深度剖析与未来展望
在当今复杂多变的资本市场中,每一只股票的波动都牵动着无数投资者的心弦,恒林股份,作为一家在A股市场内颇具影响力的上市公司,其股票行情不仅反映了公司自身的经营状况,也成为了市场风向标的一部分,本文将通过对恒林股份近期股票行情的深度剖析,结合宏观经济环境、行业趋势以及公司基本面等多重因素,为投资者提供一份全面的参考……
2025/04/11
-
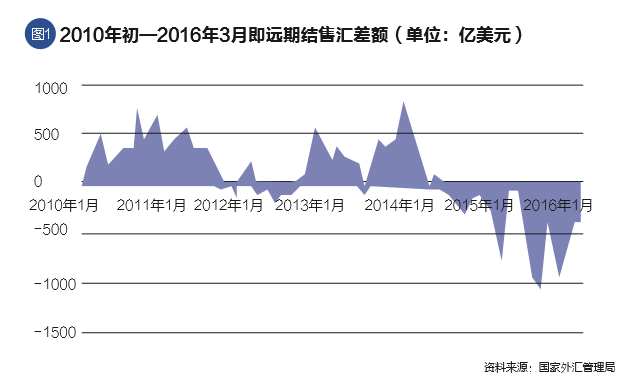
人民币汇率走势的深度剖析与未来展望
在全球化经济的大潮中,汇率作为国家间经济往来的重要桥梁,其波动不仅影响着国际贸易的平衡,也深刻影响着国内经济的稳定与发展,作为全球第二大经济体,中国的人民币汇率走势更是全球关注的焦点,本文将深入分析近期人民币汇率的走势特点、影响因素以及未来可能的发展趋势,旨在为读者提供全面而深入的洞见,近期人民币汇率走势回顾自……
2025/04/10
-
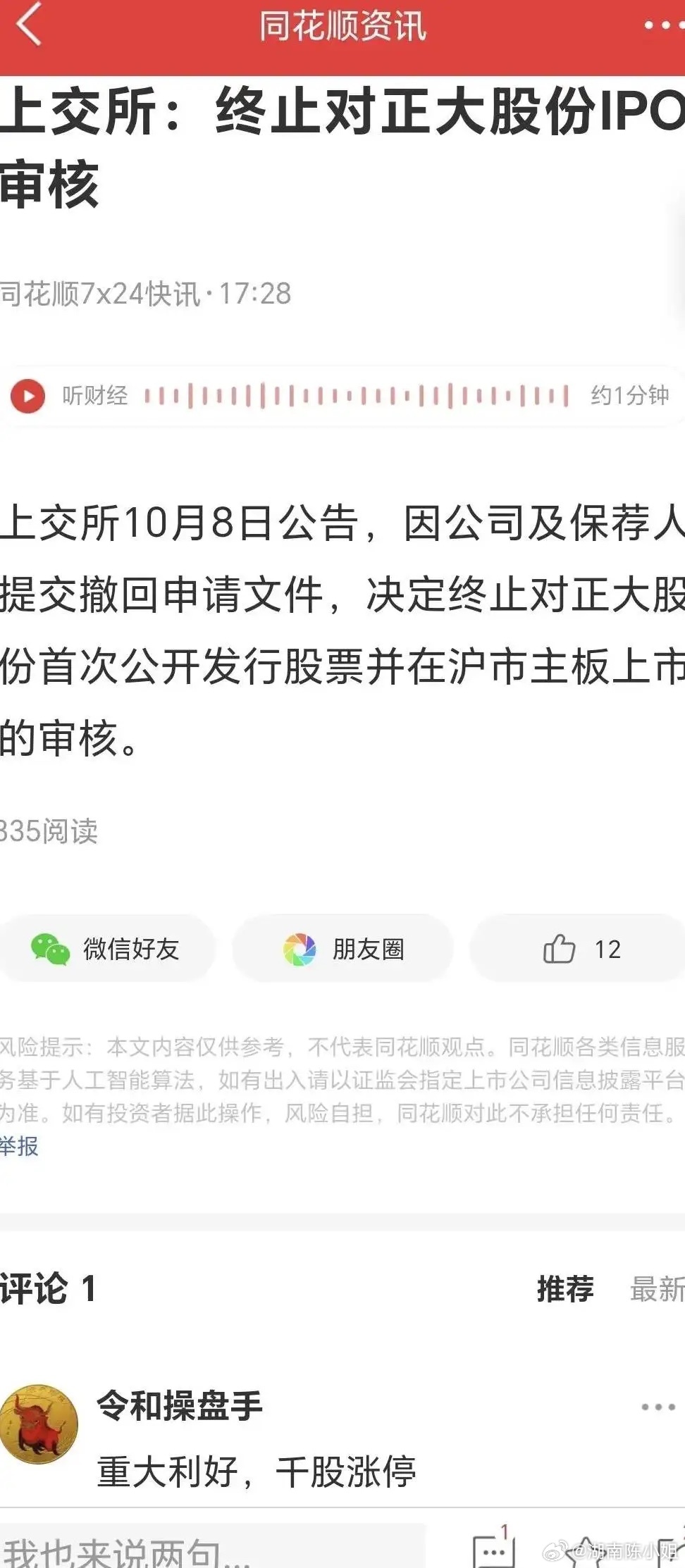
正大集团股票,多元化布局下的稳健增长与未来展望
在当今全球化的经济浪潮中,企业如何通过多元化战略实现持续稳健的增长,是每一个投资者和企业家关注的焦点,正大集团,作为一家拥有百年历史、业务遍布全球的多元化跨国企业集团,其股票表现不仅反映了企业自身的经营实力,也成为了市场动态的晴雨表,本文将深入探讨正大集团股票的概况、其多元化战略的布局、近期市场表现以及未来发展……
2025/04/10
-
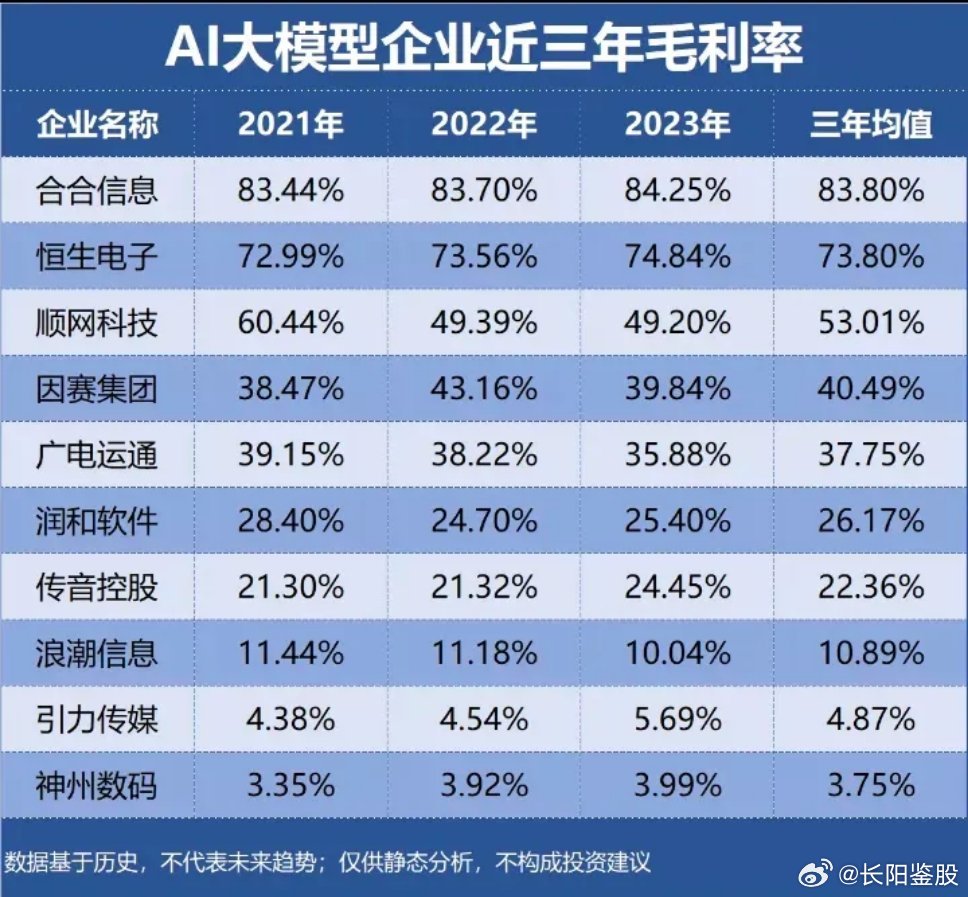
探索AI大模型背后的投资机遇,揭秘AI大模型相关股票
随着人工智能技术的飞速发展,特别是以深度学习为代表的AI大模型(如GPT、DALL-E等)的崛起,这一领域不仅在科研界引发了广泛关注,也在资本市场中掀起了投资热潮,AI大模型不仅在自然语言处理、图像生成、语音识别等应用场景中展现出巨大潜力,还为相关产业链上的企业带来了前所未有的发展机遇,本文将深入探讨AI大模型……
2025/04/12




暂无评论